Feature Scaling, also known as Data Normalisation, is a data preprocessing technique used in Machine Learning to normalise the range of predictor variables (i.e. independent variables, or features).
This is done to ensure that all the input variables have values on a normalised range. Since ranges of values can be widely different, and many Machine Learning algorithms use some notion of distance between data points, features with broader ranges will have a stronger impact on the computation of such distance.
By scaling the features into a normalised range, their contribution to the final result will be about the same.
There are several methods to perform feature scaling, common examples include Data Standardisation and Min-Max Normalisation.
Data Standardisation
Each predictor variable is transformed by subtracting its mean and dividing by the standard deviation. The resulting distribution is centred in zero and has unit variance.
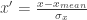
Min-Max Normalisation
Also called rescaling, the transformed values are in the [0, 1] range. Each predictor variable is transformed by subtracting its minimum value and dividing by the difference between maximum and minimum value.
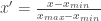
The min-max normalisation approach can be generalised to produce transformed variables with values in any [a, b] range, using the following formula:
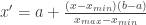
Do all Machine Learning algorithms need feature scaling?
Algorithms based on distance/similarity and curve fitting require scaling (kNN, SVM, Neural Networks, Linear/Logistic Regression).
Tree-based algorithms (Random Forest, XGBoost) and Naive Bayes don’t require scaling.
Scaling training/test data sets correctly
When scaling on a dataset that is going to be used for supervised learning using a train/test split, we need to re-use the training parameters to transform the test data set. By “training parameters” in this context we mean the relevant statistics like mean and standard deviation for data normalisation.
Why do we need to compute these statistics on the training set only? When using a trained model to make predictions, the test data should be “new and unseen”, i.e. not available at the time the model is built.
In Python/scikit-learn, this translates roughly to the following:
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaled_train_data = scaler.fit_transform(train_data) scaled_test_data = scaler.transform(test_data)
The first function fit_transform() computes the mean and standard deviation on the training data, while the second function transform() re-uses those statistics and applies them to transform the test data.

