Sentiment Analysis is one of the interesting applications of text analytics. Although the term is often associated with sentiment classification of documents, broadly speaking it refers to the use of text analytics approaches applied to the set of problems related to identifying and extracting subjective material in text sources.
This article continues the series on mining Twitter data with Python, describing a simple approach for Sentiment Analysis and applying it to the rubgy data set (see Part 4).
Tutorial Table of Contents:
- Part 1: Collecting data
- Part 2: Text Pre-processing
- Part 3: Term Frequencies
- Part 4: Rugby and Term Co-Occurrences
- Part 5: Data Visualisation Basics
- Part 6: Sentiment Analysis Basics (this article)
- Part 7: Geolocation and Interactive Maps
A Simple Approach for Sentiment Analysis
The technique we’re discussing in this post has been elaborated from the traditional approach proposed by Peter Turney in his paper Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews. A lot of work has been done in Sentiment Analysis since then, but the approach has still an interesting educational value. In particular, it is intuitive, simple to understand and to test, and most of all unsupervised, so it doesn’t require any labelled data for training.
Firstly, we define the Semantic Orientation (SO) of a word as the difference between its associations with positive and negative words. In practice, we want to calculate “how close” a word is with terms like good and bad. The chosen measure of “closeness” is Pointwise Mutual Information (PMI), calculated as follows (t1 and t2 are terms):

In Turney’s paper, the SO of a word was calculated against excellent and poor, but of course we can extend the vocabulary of positive and negative terms. Using 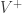
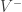
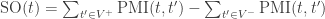
We can build our own list of positive and negative terms, or we can use one of the many resources available on-line, for example the opinion lexicon by Bing Liu.
Computing Term Probabilities
In order to compute 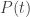
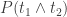
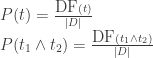
In the previous articles, the document frequency for single terms was stored in the dictionaries count_single and count_stop_single (the latter doesn’t store stop-words), while the document frequency for the co-occurrencies was stored in the co-occurrence matrix com
This is how we can compute the probabilities:
# n_docs is the total n. of tweets
p_t = {}
p_t_com = defaultdict(lambda : defaultdict(int))
for term, n in count_stop_single.items():
p_t[term] = n / n_docs
for t2 in com[term]:
p_t_com[term][t2] = com[term][t2] / n_docs
Computing the Semantic Orientation
Given two vocabularies for positive and negative terms:
positive_vocab = [
'good', 'nice', 'great', 'awesome', 'outstanding',
'fantastic', 'terrific', ':)', ':-)', 'like', 'love',
# shall we also include game-specific terms?
# 'triumph', 'triumphal', 'triumphant', 'victory', etc.
]
negative_vocab = [
'bad', 'terrible', 'crap', 'useless', 'hate', ':(', ':-(',
# 'defeat', etc.
]
We can compute the PMI of each pair of terms, and then compute the
Semantic Orientation as described above:
pmi = defaultdict(lambda : defaultdict(int))
for t1 in p_t:
for t2 in com[t1]:
denom = p_t[t1] * p_t[t2]
pmi[t1][t2] = math.log2(p_t_com[t1][t2] / denom)
semantic_orientation = {}
for term, n in p_t.items():
positive_assoc = sum(pmi[term][tx] for tx in positive_vocab)
negative_assoc = sum(pmi[term][tx] for tx in negative_vocab)
semantic_orientation[term] = positive_assoc - negative_assoc
The Semantic Orientation of a term will have a positive (negative) value if the term is often associated with terms in the positive (negative) vocabulary. The value will be zero for neutral terms, e.g. the PMI’s for positive and negative balance out, or more likely a term is never observed together with other terms in the positive/negative vocabularies.
We can print out the semantic orientation for some terms:
semantic_sorted = sorted(semantic_orientation.items(),
key=operator.itemgetter(1),
reverse=True)
top_pos = semantic_sorted[:10]
top_neg = semantic_sorted[-10:]
print(top_pos)
print(top_neg)
print("ITA v WAL: %f" % semantic_orientation['#itavwal'])
print("SCO v IRE: %f" % semantic_orientation['#scovire'])
print("ENG v FRA: %f" % semantic_orientation['#engvfra'])
print("#ITA: %f" % semantic_orientation['#ita'])
print("#FRA: %f" % semantic_orientation['#fra'])
print("#SCO: %f" % semantic_orientation['#sco'])
print("#ENG: %f" % semantic_orientation['#eng'])
print("#WAL: %f" % semantic_orientation['#wal'])
print("#IRE: %f" % semantic_orientation['#ire'])
Different vocabularies will produce different scores. Using the opinion lexicon from Bing Liu, this is what we can observed on the Rugby data-set:
# the top positive terms
[('fantastic', 91.39950482011552), ('@dai_bach', 90.48767241244532), ('hoping', 80.50247748725415), ('#it', 71.28333427277785), ('days', 67.4394844955977), ('@nigelrefowens', 64.86112716005566), ('afternoon', 64.05064208341855), ('breathtaking', 62.86591435212975), ('#wal', 60.07283361352875), ('annual', 58.95378954406133)]
# the top negative terms
[('#england', -74.83306534609066), ('6', -76.0687215594536), ('#itavwal', -78.4558633116863), ('@rbs_6_nations', -80.89363516601993), ("can't", -81.75379628180468), ('like', -83.9319149443813), ('10', -85.93073078165587), ('italy', -86.94465165178258), ('#engvfra', -113.26188957010228), ('ball', -161.82146824640125)]
# Matches
ITA v WAL: -78.455863
SCO v IRE: -73.487661
ENG v FRA: -113.261890
# Individual team
#ITA: 53.033824
#FRA: 14.099372
#SCO: 4.426723
#ENG: -0.462845
#WAL: 60.072834
#IRE: 19.231722
Some Limitations
The PMI-based approach has been introduced as simple and intuitive, but of course it has some limitations. The semantic scores are calculated on terms, meaning that there is no notion of “entity” or “concept” or “event”. For example, it would be nice to aggregate and normalise all the references to the team names, e.g. #ita, Italy and Italia should all contribute to the semantic orientation of the same entity. Moreover, do the opinions on the individual teams also contribute to the overall opinion on a match?
Some aspects of natural language are also not captured by this approach, more notably modifiers and negation: how do we deal with phrases like not bad (this is the opposite of just bad) or very good (this is stronger than just good)?
Summary
This article has continued the tutorial on mining Twitter data with Python introducing a simple approach for Sentiment Analysis, based on the computation of a semantic orientation score which tells us whether a term is more closely related to a positive or negative vocabulary. The intuition behind this approach is fairly simple, and it can be implemented using Pointwise Mutual Information as a measure of association. The approach has of course some limitations, but it’s a good starting point to get familiar with Sentiment Analysis.
- Part 1: Collecting data
- Part 2: Text Pre-processing
- Part 3: Term Frequencies
- Part 4: Rugby and Term Co-Occurrences
- Part 5: Data Visualisation Basics
- Part 6: Sentiment Analysis Basics (this article)
- Part 7: Geolocation and Interactive Maps
