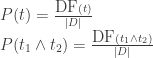Last week I had a long weekend at PyCon UK 2016 in Cardiff, and it’s been a fantastic experience! Great talks, great friends/colleagues and lots of ideas.
On Monday 19th, on the last day of the conference, my friend Miguel and I have run a tutorial/workshop on Natural Language Processing in Python (the GitHub repo contains the Jupyter notebooks we used as well as some slides for an introduction).
Our NLP tutorial
Since I’ve already mentioned it, I’ll start from the end :)
The tutorial was tailored for NLP beginners and, as I mentioned explicitly at the very beginning, I wasn’t there to impress the experts. Rather, the whole point was to get the attendees a bit curious about Natural Language Processing, and to show them what you can do with a few lines of Python.
Overall, I think we’ve been quite lucky as we had the perfect audience: the right number of people (around 20+) with a bit of Python knowledge but not much NLP knowledge.
We only had some minor hiccups with the installation process, which is something we’re going to work on to make it smoother and more beginner-friendly. In particular the things I’d like to improve are:
add some testing / pre-flight checks, e.g. “how do I know that the environment is set up correctly?”(Miguel has already added this)- support for Windows: I’m quite useless with trouble-shooting Windows issues, but a couple of attendees had some troubles with the installation process not going too smoothly; maybe some virtual machine setup will be helpful
I also think having the material available in advance, so the attendees can start setting up the environment is very helpful. Most of them were quite engaged and I received a couple of “bug reports” on-the-fly, even a pull request that improved the installation process (thanks!)
Last but not least, I was also happy to give out a copy of my book (Mastering Social Media Mining with Python) that I had with me (the raffle was implemented on the spot through random.choice(), and the book went to Paivi from Django Girls).
I’ll give a shorter version of this tutorial at PyCon Ireland later this year, so in case you’ll be around, I’ll see you there :)
Unfortunately, the tutorials were not recorded so there is no video on-line, but the slides are in the GitHub repo so please dig in and send feedback if you have any.
The Open Day
Thursday 15th was “day zero” of the conference, hosted at Cardiff University. The ticket was free, although there was limited capacity. The day was aimed at introducing the new audience to Python and PyCon. We haven’t seen much Python code on that day, as the talks were mainly for newcomers, yet we had a lot of food for thoughs. This is a great way to introduce more people to Python and to show them how the community is friendly and happy to get more beginners on board.
Teachers, Kids and Education
One of the main themes of the conference was Education. Friday 16th, the first day of the main event, was labelled “Teachers Day”, while Saturday 17th was “Kids Day”. The effort to make CS education more accessible for kids was very clear, and some of the initiatives were really spot-on. In particular, some of the kids have been able to hack some small project together in a very short time, and they delivered a “show and tell” session at the end of the second day. I think their creativity and the fact that they were standing in front of a crowd of 500+ developers to show what they have been working on during their day have been very impressive.
Community in the Broader Sense
Another aspect that became quite clear is the strength of the Python Community. Some representatives of PyCon Poland, PyCon Switzerland and Django Europe were introducing their upcoming events. Some attendees with less economic capabilities were given the opportunity to attend, through some form of financial support (including e.g. students from India).
Representatives from PyCon Namibia and PyCon Zimbabwe were also attending and they discussed some of the challenges they are facing while building a local community in their countries.
In particular, the work Jessica from PyNAM is carrying out with young learners is extremely inspiring and deserves more visibility (link to the video of her talk).
Accessibility for Everybody
One of the features that I’ve never experienced in a conference so far was the speech-to-text transcription. During the talks, the speech-to-text team have been very busy writing down what the speakers were saying in real-time. While this is sometimes considered an accessibility feature which might benefit only deaf users, it turned out live captions are extremely beneficial for everybody. Firstly, not all the non-deaf attendees have perfect hearing. Secondly, not everybody is an English native speaker (both speakers and audience), so a word might be missed, or an accent might cause some confusion. Lastly, not every attendee is paying full attention to every talk for the whole talk: sometimes towards the end of the day, you just switch off for a moment and the live captions allow you to catch up.
Providing some accessibility feature turned out to be beneficial for everybody.
Shout out to the Organisers
Organising such a big event (500+ attendees) is not an easy task, so all the people who have worked hard to make this conference happen deserve a big round of applause. Not naming names here, but if you’ve been involved, thanks!
Being Interviewed about NLP
This was a bit random, in a very pleasant way. On Saturday, Miguel, Lev from RaRe Technologies and I spent some time with Kate Jarmul, who by the way just introduced her book on data wrangling, and also delivered a tutorial on the topic. The topic of the conversation was on our views, in the broader sense, about NLP / Text Analytics, how we got into this field, how we see this field evolving and so on. Apparently, this was an interview with some experts of the field, for a piece she’s writing for the O’Reilly blog (I should put an amazed emoticon here).
Using Python for …
The breadth of the topics discussed during the conference was really amazing. I think this kind of events are a great way to see what people are working on and how the tools we use every day are used by other people.
I’m not going to name any talk in particular, because there are too many good talks that deserve to be mentioned.
In terms of topics, some fields that are well covered by Python are:
- Data Science (and related topics like data cleaning, NLP and machine learning)
- Web development (with Django and so many interesting libraries)
- electronics and robotics (with Raspberry Pi, micro:bit, MicroPython etc)
- you name it :)
I’m probably not saying anything new here, but it was nice to see it in first person and step outside my data-sciency comfort zone.
Summary
Thanks to everybody who contributed to this event, and see you in Cardiff for PyCon UK 2017!



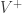 and a vocabulary of positive terms and
and a vocabulary of positive terms and 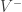 for the negative ones, the Semantic Orientation of a term t is hence defined as:
for the negative ones, the Semantic Orientation of a term t is hence defined as: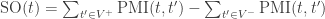
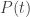 (the probability of observing the term t) and
(the probability of observing the term t) and 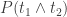 (the probability of observing the terms t1 and t2 occurring together) we can re-use some previous code to calculate
(the probability of observing the terms t1 and t2 occurring together) we can re-use some previous code to calculate