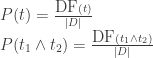Last Saturday was the closing day of the Six Nations Championship, an annual international rugby competition. Before turning on the TV to watch Italy being trashed by Wales, I decided to use this event to collect some data from Twitter and perform some exploratory text analysis on something more interesting than the small list of my tweets.
This article continues the tutorial on Twitter Data Mining, re-using what we discussed in the previous articles with some more realistic data. It also expands the analysis by introducing the concept of term co-occurrence.
Tutorial Table of Contents:
The Application Domain
As the name suggests, six teams are involved in the competition: England, Ireland, Wales, Scotland, France and Italy. This means that we can expect the event to be tweeted in multiple languages (English, French, Italian, Welsh, Gaelic, possibly other languages as well), with English being the major language. Assuming the team names will be mentioned frequently, we could decide to look also for their nicknames, e.g. Les Bleus for France or Azzurri for Italy. During the last day of the competition, three matches are played sequentially. Three teams in particular had a shot for the title: England, Ireland and Wales. At the end, Ireland won the competition but everything was open until the very last minute.
Setting Up
I used the streaming API to download all the tweets containing the string #rbs6nations during the day. Obviously not all the tweets about the event contained the hashtag, but this is a good baseline. The time frame for the download was from around 12:15PM to 7:15PM GMT, that is from about 15 minutes before the first match, to about 15 minutes after the last match was over. At the end, more than 18,000 tweets have been downloaded in JSON format, making for about 75Mb of data. This should be small enough to quickly do some processing in memory, and at the same time big enough to observe something possibly interesting.
The textual content of the tweets has been pre-processed with tokenisation and lowercasing using the preprocess() function introduced in Part 2 of the tutorial.
Interesting terms and hashtags
Following what we discussed in Part 3 (Term Frequencies), we want to observe the most common terms and hashtags used during day. If you have followed the discussion about creating different lists of tokens in order to capture terms without hashtags, hashtags only, removing stop-words, etc. you can play around with the different lists.
This is the unsurprising list of top 10 most frequent terms (terms_only in Part 3) in the data set.
[('ireland', 3163), ('england', 2584), ('wales', 2271), ('…', 2068), ('day', 1479), ('france', 1380), ('win', 1338), ('rugby', 1253), ('points', 1221), ('title', 1180)]
The first three terms correspond to the teams who had a go for the title. The frequencies also respect the order in the final table. The fourth term is instead a punctuation mark that we missed and didn’t include in the list of stop-words. This is because string.punctuation only contains ASCII symbols, while here we’re dealing with a unicode character. If we dig into the data, there will be more examples like this, but for the moment we don’t worry about it.
After adding the suspension-points symbol to the list of stop-words, we have a new entry at the end of the list:
[('ireland', 3163), ('england', 2584), ('wales', 2271), ('day', 1479), ('france', 1380), ('win', 1338), ('rugby', 1253), ('points', 1221), ('title', 1180), ('🍀', 1154)]
Interestingly, a new token we didn’t account for, an Emoji symbol (in this case, the Irish Shamrock).
If we have a look at the most common hashtags, we need to consider that #rbs6nations will be by far the most common token (that’s our search term for downloading the tweets), so we can exclude it from the list. This leave us with:
[('#engvfra', 1701), ('#itavwal', 927), ('#rugby', 880), ('#scovire', 692), ('#ireland', 686), ('#angfra', 554), ('#xvdefrance', 508), ('#crunch', 500), ('#wales', 446), ('#england', 406)]
We can observe that the most common hashtags, a part from #rugby, are related to the individual matches. In particular England v France has received the highest number of mentions, probably being the last match of the day with a dramatic finale. Something interesting to notice is that a fair amount of tweets also contained terms in French: the count for #angfra should in fact be added to #engvfra. Those unfamiliar with rugby probably wouldn’t recognise that also #crunch should be included with #EngvFra match, as Le Crunch is the traditional name for this event. So by far, the last match has received a lot of attention.
Term co-occurrences
Sometimes we are interested in the terms that occur together. This is mainly because the context gives us a better insight about the meaning of a term, supporting applications such as word disambiguation or semantic similarity. We discussed the option of using bigrams in the previous article, but we want to extend the context of a term to the whole tweet.
We can refactor the code from the previous article in order to capture the co-occurrences. We build a co-occurrence matrix com such that com[x][y] contains the number of times the term x has been seen in the same tweet as the term y:
from collections import defaultdict
# remember to include the other import from the previous post
com = defaultdict(lambda : defaultdict(int))
# f is the file pointer to the JSON data set
for line in f:
tweet = json.loads(line)
terms_only = [term for term in preprocess(tweet['text'])
if term not in stop
and not term.startswith(('#', '@'))]
# Build co-occurrence matrix
for i in range(len(terms_only)-1):
for j in range(i+1, len(terms_only)):
w1, w2 = sorted([terms_only[i], terms_only[j]])
if w1 != w2:
com[w1][w2] += 1
While building the co-occurrence matrix, we don’t want to count the same term pair twice, e.g. com[A][B] == com[B][A], so the inner for loop starts from i+1 in order to build a triangular matrix, while sorted will preserve the alphabetical order of the terms.
For each term, we then extract the 5 most frequent co-occurrent terms, creating a list of tuples in the form ((term1, term2), count):
com_max = []
# For each term, look for the most common co-occurrent terms
for t1 in com:
t1_max_terms = sorted(com[t1].items(), key=operator.itemgetter(1), reverse=True)[:5]
for t2, t2_count in t1_max_terms:
com_max.append(((t1, t2), t2_count))
# Get the most frequent co-occurrences
terms_max = sorted(com_max, key=operator.itemgetter(1), reverse=True)
print(terms_max[:5])
The results:
[(('6', 'nations'), 845), (('champions', 'ireland'), 760), (('nations', 'rbs'), 742), (('day', 'ireland'), 731), (('ireland', 'wales'), 674)]
This implementation is pretty straightforward, but depending on the data set and on the use of the matrix, one might want to look into tools like scipy.sparse for building a sparse matrix.
We could also look for a specific term and extract its most frequent co-occurrences. We simply need to modify the main loop including an extra counter, for example:
search_word = sys.argv[1] # pass a term as a command-line argument
count_search = Counter()
for line in f:
tweet = json.loads(line)
terms_only = [term for term in preprocess(tweet['text'])
if term not in stop
and not term.startswith(('#', '@'))]
if search_word in terms_only:
count_search.update(terms_only)
print("Co-occurrence for %s:" % search_word)
print(count_search.most_common(20))
The outcome for “ireland”:
[('champions', 756), ('day', 727), ('nations', 659), ('wales', 654), ('2015', 638), ('6', 613), ('rbs', 585), ('http://t.co/y0nvsvayln', 559), ('🍀', 526), ('10', 522), ('win', 377), ('england', 377), ('twickenham', 361), ('40', 360), ('points', 356), ('sco', 355), ('ire', 355), ('title', 346), ('scotland', 301), ('turn', 295)]
The outcome for “rugby”:
[('day', 476), ('game', 160), ('ireland', 143), ('england', 132), ('great', 105), ('today', 104), ('best', 97), ('well', 90), ('ever', 89), ('incredible', 87), ('amazing', 84), ('done', 82), ('amp', 71), ('games', 66), ('points', 64), ('monumental', 58), ('strap', 56), ('world', 55), ('team', 55), ('http://t.co/bhmeorr19i', 53)]
Overall, quite interesting.
Summary
This article has discussed a toy example of Text Mining on Twitter, using some realistic data taken during a sport event. Using what we have learnt in the previous episodes, we have downloaded some data using the streaming API, pre-processed the data in JSON format and extracted some interesting terms and hashtags from the tweets. The article has also introduced the concept of term co-occurrence, shown how to build a co-occurrence matrix and discussed how to use it to find some interesting insight.
@MarcoBonzanini

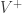 and a vocabulary of positive terms and
and a vocabulary of positive terms and 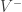 for the negative ones, the Semantic Orientation of a term t is hence defined as:
for the negative ones, the Semantic Orientation of a term t is hence defined as: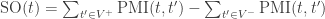
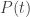 (the probability of observing the term t) and
(the probability of observing the term t) and 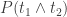 (the probability of observing the terms t1 and t2 occurring together) we can re-use some previous code to calculate
(the probability of observing the terms t1 and t2 occurring together) we can re-use some previous code to calculate