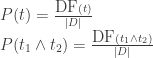Search-as-you-type is an interesting feature of modern search engines, that allows users to have an instant feedback related to their search, while they are still typing a query.
In this tutorial, we discuss how to implement this feature in a custom search engine built with Elasticsearch and Python/Flask on the backend side, and AngularJS for the frontend.
The full code is available at https://github.com/bonzanini/CheerMeApp-demo. If you go through the code, have a look at the readme file first, in particular to understand the limitations of the code.
This first part describes the details of the backend, i.e. Elasticsearch and Python/Flask.
Update: the second part of this tutorial has been published and it discusses the front-end in AngularJS.
Overall Architecture
As this demo was prototyped during International Beer Day 2015, we’ll build a small database of beers, each of which will be defined by a name, the name of its producer, a list of beer styles and a textual description. The idea is to make all these data available for search in one coherent interface, so you can just type in the name of your favourite brew, or aspects like “light and fruity”.
Our system is made up of three components:
- Elasticsearch: used as data storage and for its search capabilities.
- Python/Flask Microservice: the backend component that has access to Elasticsearch and provides a RESTful API for the frontend.
- AngularJS UI: the frontend that requests data to the backend microservice.
There are two types of documents – beers and styles. While styles are simple strings with the style name, beers are more complex. This is an example:
{
"name": "Raspberry Wheat Beer",
"styles": ["Wheat Ale", "Fruit Beer"],
"abv": 5.0,
"producer": "Meantime Brewing London",
"description": "Based on a pale, lightly hopped wheat beer, the refreshingly crisp fruitiness, aroma and rich colour come from the addition of fresh raspberry puree during maturation."
}
(the description is taken from the producer’s website in August 2015).
Setting Up Elasticsearch
The mapping for the Elasticsearch types is fairly straightforward. The key detail in order to enable the search-as-you-type feature is how to perform partial matching over strings.
One option is to use wildcard queries over not_analyzed fields, similar to a ... WHERE field LIKE '%foobar%' query in SQL, but this is usually too expensive. Another option is to change the analysis chain in order to index also partial strings: this will result in a bigger index but in faster queries.
We can achieve our goal by using the edge_ngram filter as part of a custom analyser, e.g.:
{
"settings": {
"number_of_shards" : 1,
"number_of_replicas": 0,
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 15
}
},
"analyzer": {
"autocomplete": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter"
]
}
}
}
}
}
In this example, the custom filter will allow to index substrings of 2-to-15 characters. You can customise these boundaries, but indexing unigram (min_gram: 1) probably will cause any query to match any document, and words longer than 15 chars are rarely observed (e.g. we’re not dealing with long compounds).
Once the custom analysis chain is defined, the mapping is easy:
{
"mappings": {
"beers": {
"properties": {
"name": {"type": "string", "index_analyzer": "autocomplete", "search_analyzer": "standard"},
"styles": {"type": "string", "index_analyzer": "autocomplete", "search_analyzer": "standard"},
"abv": {"type": "float"},
"producer": {"type": "string", "index_analyzer": "autocomplete", "search_analyzer": "standard"},
"description": {"type": "string", "index_analyzer": "autocomplete", "search_analyzer": "standard"}
}
},
"styles": {
"properties": {
"name": {"type": "string", "index": "not_analyzed"}
}
}
}
}
Populating Elasticsearch
Assuming you have Elasticsearch up-and-running locally on localhost:9200 (the default), you can simply type make index from the demo folder.
This will firstly try to delete an index called cheermeapp (you’ll see a missing index error the first time, as there is of course no index yet). Secondly, the index is recreated by pushing the mapping file to Elasticsearch, and finally some data are indexed using the _bulk API.
If you want to see some data, you can now type:
curl -XPOST http://localhost:9200/cheermeapp/beers/_search?pretty -d '{"query": {"match_all": {}}}'
A Python Microservice with Flask
As the Elasticsearch service is by default open to any connection, it is common practice to put it behind a custom web-service. Luckily, Flask and its Flask-RESTful extension allow use to quickly set up a RESTful microservice which exposes some useful endpoints. These endpoints will then be queries by the frontend.
If you’re following the code from the repo, the recommendation is to set-up a local virtualenv as described in the readme, in order to install the dependencies locally. You can see the full code for the backend microservice is the backend folder.
In particular, in backend/__init__.py we declare the Flask application as:
from flask import Flask from flask_restful import reqparse, Resource, Api from flask.ext.cors import CORS from . import config import requests import json app = Flask(__name__) CORS(app) # required for Cross-origin Request Sharing api = Api(app)
By setting up the backend app as Python package (a folder with an __init__.py file), the script to run this app is extremely simple:
# runbackend.py
from backend import app
if __name__ == '__main__':
app.run(debug=True)
This code just sets up an empty web-service: we need to implement the endpoints and the related resources. One nice aspect of Flask-RESTful is that it allows to define the resources as Python classes, adding the endpoints with minimal effort.
For example, in backend/__init__.py we can continue defining the following:
class Beer(Resource):
def get(self, beer_id):
# the base URL for a "beers" object in Elasticsearch, e.g.
# http://localhost:9200/cheermeapp/beers/<beer_id>
url = config.es_base_url['beers']+'/'+beer_id
# query Elasticsearch
resp = requests.get(url)
data = resp.json()
# Return the full Elasticsearch object as a result
beer = data['_source']
return beer
def delete(self, beer_id):
# same as above
url = config.es_base_url['beers']+'/'+beer_id
# Query Elasticsearch
resp = requests.delete(url)
# return the response
data = resp.json()
return data
# The API URLs all start with /api/v1, in case we need to implement different versions later
api.add_resource(Beer, config.api_base_url+'/beers/<beer_id>')
class BeerList(Resource):
def get(self):
# same as above
url = config.es_base_url['beers']+'/_search'
# we retrieve all the beers (well, at least the first 100)
# Limitation: pagination to be implemented
query = {
"query": {
"match_all": {}
},
"size": 100
}
# query Elasticsearch
resp = requests.post(url, data=json.dumps(query))
data = resp.json()
# build an array of results and return it
beers = []
for hit in data['hits']['hits']:
beer = hit['_source']
beer['id'] = hit['_id']
beers.append(beer)
return beers
api.add_resource(BeerList, config.api_base_url+'/beers')
The above code implements the GET and DELETE methods for /api/v1/beers/, which respectively retrieve and delete a specific beer, and the GET method for the /api/v1/beers, which retrieve the full list of beers. In the repo, you can also observe the POST method implemented on the BeerList class, which allows to create a new beer.
Design note: given that create-read-update operations, as well as the search, will work on the same data model, it’s probably more sensible to de-couple the object model from the endpoint definition, e.g. by defining a BeerModel and call it from the related resources.
From the repo, you can also see the implementation of the /api/v1/styles endpoint.
One the backend is running, the service will be accessible at localhost:5000 (the default option for Flask). You can test it with:
curl -XGET http://localhost:5000/api/v1/beers
The Search Functionality
Besides serving “items”, our microservice also incorporates a search functionality:
class Search(Resource):
def get(self):
# parse the query: ?q=[something]
parser.add_argument('q')
query_string = parser.parse_args()
# base search URL
url = config.es_base_url['beers']+'/_search'
# Query Elasticsearch
query = {
"query": {
"multi_match": {
"fields": ["name", "producer", "description", "styles"],
"query": query_string['q'],
"type": "cross_fields",
"use_dis_max": False
}
},
"size": 100
}
resp = requests.post(url, data=json.dumps(query))
data = resp.json()
# Build an array of results
beers = []
for hit in data['hits']['hits']:
beer = hit['_source']
beer['id'] = hit['_id']
beers.append(beer)
return beers
api.add_resource(Search, config.api_base_url+'/search')
The above code will make a /api/v1/search endpoint available for custom queries.
The interface with Elasticsearch is a custom multi_match and cross_fields query, which searches over the name, producer, styles and description fields, i.e. all the textual fields.
By default, Elasticsearch performs multi_match queries as best_fields, which means only the field with the best score will give the overall score for a particular document. In our case, we prefer to have all the fields to contribute to the final score. In particular, we want to avoid longer fields like the description to be penalised by the document length normalisation.
Design note: notice how we’re duplicating the same code at the end of Search.get() and BeerList.get(), we should really decouple this.
You can test the search service with:
curl -XGET http://localhost:5000/api/v1/search?q=lon # will retrieve all the beers matching "lon", e.g. containing the string "london"
The next step is to create the frontend to query the microservice and show the results in a nice UI. The implementation is already available in the repo, and will be discussed in the next article.
Summary
This article sets up the backend side of a search-as-you-type application.
The scenario is the CheerMeApp application, a mini database of beers with names, styles and descriptions. The search application can match any of these fields while the user is still typing, i.e. with partial string matching.
The backend side of the app is based on Elasticsearch for the data storage and search functionality. In particular, by indexing the substrings (n-grams) we allow for partial string matching, by increasing the size of the index on disk without hurting query-time performances.
The data storage is “hidden” behind a Python/Flask microservice, which provides endpoint for a client to query. In particular, we have seen how the Flask-RESTful extension allows to quickly create RESTful applications by simply declaring the resources as Python classes.
The next article will discuss some aspects of the frontend, developed in AngularJS, and how to link it with the backend.



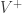 and a vocabulary of positive terms and
and a vocabulary of positive terms and 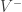 for the negative ones, the Semantic Orientation of a term t is hence defined as:
for the negative ones, the Semantic Orientation of a term t is hence defined as: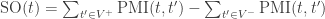
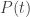 (the probability of observing the term t) and
(the probability of observing the term t) and 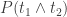 (the probability of observing the terms t1 and t2 occurring together) we can re-use some previous code to calculate
(the probability of observing the terms t1 and t2 occurring together) we can re-use some previous code to calculate