In the past few weeks, I’ve been playing around with some third-party Web APIs for Text Analytics, mainly for some side projects. This article is a short write-up of my experience with the Dandelion API.
Notice: I’m not affiliated with dandelion.eu and I’m not a paying customer, I’m simply using their basic (i.e. free) plan which is, at the moment, more than enough for my toy examples.
Quick Overview on the Dandelion API
The Dandelion API has a set of endpoints, for different text analytics tasks. In particular, they offer semantic analysis features for:
- Entity Extraction
- Text Similarity
- Text Classification
- Language Detection
- Sentiment Analysis
As my attention was mainly on entity extraction and sentiment analysis, I’ll focus this article on the two related endpoints.
The basic (free) plan for Dandelion comes with a rate of 1,000 units/day (or approx 30,000 units/month). Different endpoints have a different unit cost, i.e. the entity extraction and sentiment analysis cost 1 unit per request, while the text similarity costs 3 units per request. If you need to pass a URL or HTML instead of plain text, you’ll need to add an extra unit. The API is optimised for short text, so if you’re passing more than 4,000 characters, you’ll be billed extra units accordingly.
Getting started
In order to test the Dandelion API, I’ve downloaded some tweets using the Twitter Stream API. You can have a look at a previous article to see how to get data from Twitter with Python.
As NASA recently found evidence of water on Mars, that’s one of the hot topics on social media at the moment, so let’s have a look at a couple of tweets:
- So what you’re saying is we just found water on Mars…. But we can’t make an iPhone charger that won’t break after three weeks?
- NASA found water on Mars while Chelsea fans are still struggling to find their team in the league table
(not trying to be funny with Apple/Chelsea fans here, I was trying to collect data to compare iPhone vs Android and some London football teams, but the water-on-Mars topic got all the attentions).
The Dandelion API also provides a Python client, but the use of the API is so simple that we can directly use a library like requests to communicate with the endpoints. If it’s not installed yet, you can simply use pip:
pip install requests
Entity Extraction
Assuming you’ve signed up for the service, you will have an application key and an application ID. You will need them to query the service. The docs also provide all the references for the available parameters, the URI to query and the response format. App ID and key are passed via the parameters $app_id and $app_key respectively (mind the initial $ symbol).
import requests
import json
DANDELION_APP_ID = 'YOUR-APP-ID'
DANDELION_APP_KEY = 'YOUR-APP-KEY'
ENTITY_URL = 'https://api.dandelion.eu/datatxt/nex/v1'
def get_entities(text, confidence=0.1, lang='en'):
payload = {
'$app_id': DANDELION_APP_ID,
'$app_key': DANDELION_APP_KEY,
'text': text,
'confidence': confidence,
'lang': lang,
'social.hashtag': True,
'social.mention': True
}
response = requests.get(ENTITY_URL, params=payload)
return response.json()
def print_entities(data):
for annotation in data['annotations']:
print("Entity found: %s" % annotation['spot'])
if __name__ == '__main__':
query = "So what you're saying is we just found water on Mars.... But we can't make an iPhone charger that won't break after three weeks?"
response = get_entities(query)
print(json.dumps(response, indent=4))
This will produce the pretty-printed JSON response from the Dandelion API. In particular, let’s have a look at the annotations:
{
"annotations": [
{
"label": "Water on Mars",
"end": 51,
"id": 21857752,
"start": 38,
"spot": "water on Mars",
"uri": "http://en.wikipedia.org/wiki/Water_on_Mars",
"title": "Water on Mars",
"confidence": 0.8435
},
{
"label": "IPhone",
"end": 82,
"id": 8841749,
"start": 76,
"spot": "iPhone",
"uri": "http://en.wikipedia.org/wiki/IPhone",
"title": "IPhone",
"confidence": 0.799
}
],
/* more JSON output here */
}
Interesting to see that “water on Mars” is one of the entities (rather than just “water” and “Mars” as separate entities). Both entities are linked to their Wikipedia page, and both come with a high level of confidence. It would be even more interesting to see a different granularity for entity extraction, as in this case there is an explicit mention of one specific aspect of the iPhone (the battery charger).
The code snippet above defines also a print_entities() function, that you can use to substitute the print statement, if you want to print out only the entity references. Keep in mind that the attribute spot will contain the text as it appears in the original input. The other attributes of the output are pretty much self-explanatory, but you can check out the docs for further details.
If we run the same code using the Chelsea-related tweet above, we can find the following entities:
{
"annotations": [
{
"uri": "http://en.wikipedia.org/wiki/NASA",
"title": "NASA",
"spot": "NASA",
"id": 18426568,
"end": 4,
"confidence": 0.8525,
"start": 0,
"label": "NASA"
},
{
"uri": "http://en.wikipedia.org/wiki/Water_on_Mars",
"title": "Water on Mars",
"spot": "water on Mars",
"id": 21857752,
"end": 24,
"confidence": 0.8844,
"start": 11,
"label": "Water on Mars"
},
{
"uri": "http://en.wikipedia.org/wiki/Chelsea_F.C.",
"title": "Chelsea F.C.",
"spot": "Chelsea",
"id": 7473,
"end": 38,
"confidence": 0.8007,
"start": 31,
"label": "Chelsea"
}
],
/* more JSON output here */
}
Overall, it looks quite interesting.
Sentiment Analysis
Sentiment Analysis is not an easy task, especially when performed on tweets (very little context, informal language, sarcasm, etc.).
Let’s try to use the Sentiment Analysis API with the same tweets:
import requests
import json
DANDELION_APP_ID = 'YOUR-APP-ID'
DANDELION_APP_KEY = 'YOUR-APP-KEY'
SENTIMENT_URL = 'https://api.dandelion.eu/datatxt/sent/v1'
def get_sentiment(text, lang='en'):
payload = {
'$app_id': DANDELION_APP_ID,
'$app_key': DANDELION_APP_KEY,
'text': text,
'lang': lang
}
response = requests.get(SENTIMENT_URL, params=payload)
return response.json()
if __name__ == '__main__':
query = "So what you're saying is we just found water on Mars.... But we can't make an iPhone charger that won't break after three weeks?"
response = get_sentiment(query)
print(json.dumps(response, indent=4))
This will print the following output:
{
"sentiment": {
"score": -0.7,
"type": "negative"
},
/* more JSON output here */
}
The “sentiment” attribute will give us a score (from -1, totally negative, to 1, totally positive), and a type, which is one between positive, negative and neutral.
The main limitation here is not identifying explicitely the object of the sentiment. Even if we cross-reference the entities extracted in the previous paragraph, how can we programmatically link the negative sentiment with one of them? Is the negative sentiment related to finding water on Mars, or on the iPhone? As mentioned in the previous paragraph, there is also an explicit mention to the battery charger, which is not capture by the APIs and which is the target of the sentiment for this example.
The Chelsea tweet above will also produce a negative score. After downloading some more data looking for some positive tweets, I found this:
Nothing feels better than finishing a client job that you’re super happy with. Today is a good day.
The output for the Sentiment Analysis API:
{
"sentiment": {
"score": 0.7333333333333334,
"type": "positive"
},
/* more JSON output here */
}
Well, this one was probably very explicit.
Summary
Using a third-party API can be as easy as writing a couple of lines in Python, or it can be a major pain. I think the short examples here showcase that the “easy” in the title is well motivated.
It’s worth noting that this article is not a proper review of the Deandelion API, it’s more like a short diary entry of my experiments, so what I’m reporting here is not a rigorous evaluation.
Anyway, the feeling is quite positive for the Entity Extraction API. I did some test also using hash-tags with some acronyms, and the API was able to correctly point me to the related entity. Occasionally there are some pieces of text labelled as entities, completely out of scope. This happens mostly with some movie (or song, or album) titles appearing verbatim in the text, and probably labelled because of the little context you have in Twitter’s 140 characters.
On the Sentiment Analysis side, I think providing only one aggregated score for the whole text sometimes doesn’t give the full picture. While it makes sense in some sentiment classification task (e.g. movie reviews, product reviews, etc.), we have seen more and more work on aspect-based sentiment analysis, which is what provides the right level of granularity to understand more deeply what the users are saying. As I mentioned already, this is anyway not trivial.
Overall, I had some fun playing with this API and I think the authors did a good job in keeping it simple to use.



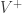 and a vocabulary of positive terms and
and a vocabulary of positive terms and 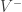 for the negative ones, the Semantic Orientation of a term t is hence defined as:
for the negative ones, the Semantic Orientation of a term t is hence defined as: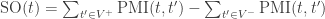
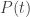 (the probability of observing the term t) and
(the probability of observing the term t) and 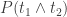 (the probability of observing the terms t1 and t2 occurring together) we can re-use some previous code to calculate
(the probability of observing the terms t1 and t2 occurring together) we can re-use some previous code to calculate